Scatter Gather Pattern: Designing High-Performing Distributed Systems
The page explains the Scatter-Gather pattern that is used to parallelize processing tasks in distributed systems. The article details the pattern, its implementation and the considerations of using it.

Introduction
In this blog post, I will explore the Scatter-Gather Pattern, a cloud scalability design that can process large amounts of data and perform time-consuming, intricate computations. The pattern works like a guide for creating distributed systems to achieve parallelism. The approach can significantly reduce processing times for an online application to cater to as many users. The idea is to break down an operation into independent tasks to achieve approximately constant response time.
What is Scatter Gather Pattern
Let us take an example to understand the problem where the pattern can be effective. Suppose an application that runs on a single-core processor. It can process an incoming request in 64 seconds to produce a result. If we migrate the same application to a 16-core processor, it can generate the same output in roughly four seconds. The multicore processor will spawn sixteen threads to work in parallel to compute the result, with a few extra microseconds for managing multiple processing threads. A four-second response time is good but still considered slugging for a web application. Upgrading the processor further, verticle scaling, will mitigate the problem, not solve it.
The Scatter-Gather pattern can solve this problem. The structure of the Scatter-Gather is like a tree, with the application controller acting as the root. When the controller receives an incoming request, it divides it into multiple independent tasks and assigns them to available leaf nodes, the “scatter” phase. Leaf nodes are multiple machines or containers available on a distributed network. Each processor leaf works independently and in parallel on its computation, producing a portion of the response. Once they have completed their task, each leaf sends its partial response back to the root, which collects them all as part of the “gather” phase. The root controller then combines the partial responses and returns the final result to the client. The diagram below pictures the pattern.
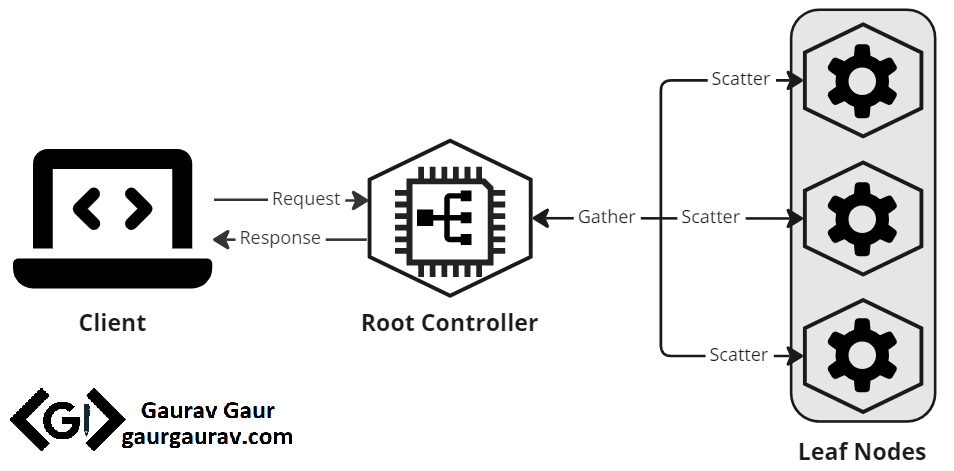 Scatter-Gather pattern illustration
Scatter-Gather pattern illustration
The strategy enables us to exploit cloud infrastructure to allocate as many virtual machines as needed and scale horizontally. The application can distribute the load dynamically to achieve the desired response time. If a particular leaf node has a high response time (e.g., due to noisy neighbours), the root controller can also redistribute the load for a quicker response. Let us examine a use case in the passage below.
Use Case
Now that we understand the pattern, let’s explore a practical use case where it can demonstrate remarkable effectiveness despite its apparent simplicity. Imagine a website of a rail company that sells tickets to its customers. Suppose a customer plans a weekend trip from London and wants to optimize expenses by identifying how far he can travel with the same budget. He submits a query to the website to list all direct trains departing from London throughout the country.
One approach to handle this task is to send individual queries to each rail operator in the UK, collect the results, and then present them to the user. However, this will be impractical, as the application issues a query at a time. To improve the efficiency of this solution, we can divide the UK into five regions: Eastern, Northwest and Central, Wales and Western, Scotland, and Southern. When a request arrives, the root controller divides it and assigns it to the five leaf nodes to process in parallel. Each leaf node concentrates on a specific region, which reduces the need to search the entire country. Each leaf node returns a list of all the direct trains from London to that region. Finally, the root controller merges all the results to create a final list to display to the customer.
Implementation Details
The previous section has demonstrated a practical use case for improving the scalability of a web application. However, it is essential to consider the following points before adopting this tactic:
1. Handling non-responsive leaf nodes
Even though the applications are using a cloud environment, there is always a possibility that machines may become unavailable due to network or infrastructure issues. Moreover, the leaf nodes might communicate with external APIs (as we saw in the example use case previously) that may not respond promptly. To mitigate these issues, the root controller must set an upper limit on response time, how long it can wait for a reply. If a leaf node does not respond within that time, the root controller can ignore it and aggregate the results it has already gathered to formulate a response for the user. This approach can minimize the impact on the user by sacrificing a small portion of the result.
2. Decoupling the root controller from processing leaf nodes
It’s crucial to avoid coupling the root controller with the leaf nodes to improve the architecture. A tight coupling between them would mean that the root controller continuously tracks working leaf nodes, leading to unnecessary overhead on the application. Instead, we can use a message broker. A pub-sub communication style can create a loosely coupled root controller and leaf nodes. Whenever there is an incoming request, the root controller broadcasts messages to the potential working leaf nodes. All the working nodes can then subscribe to the incoming message, process it, and publish their results to a separate queue. The root controller can consume the results from that queue, aggregate them, and respond to the user. The figure below illustrates the implementation.
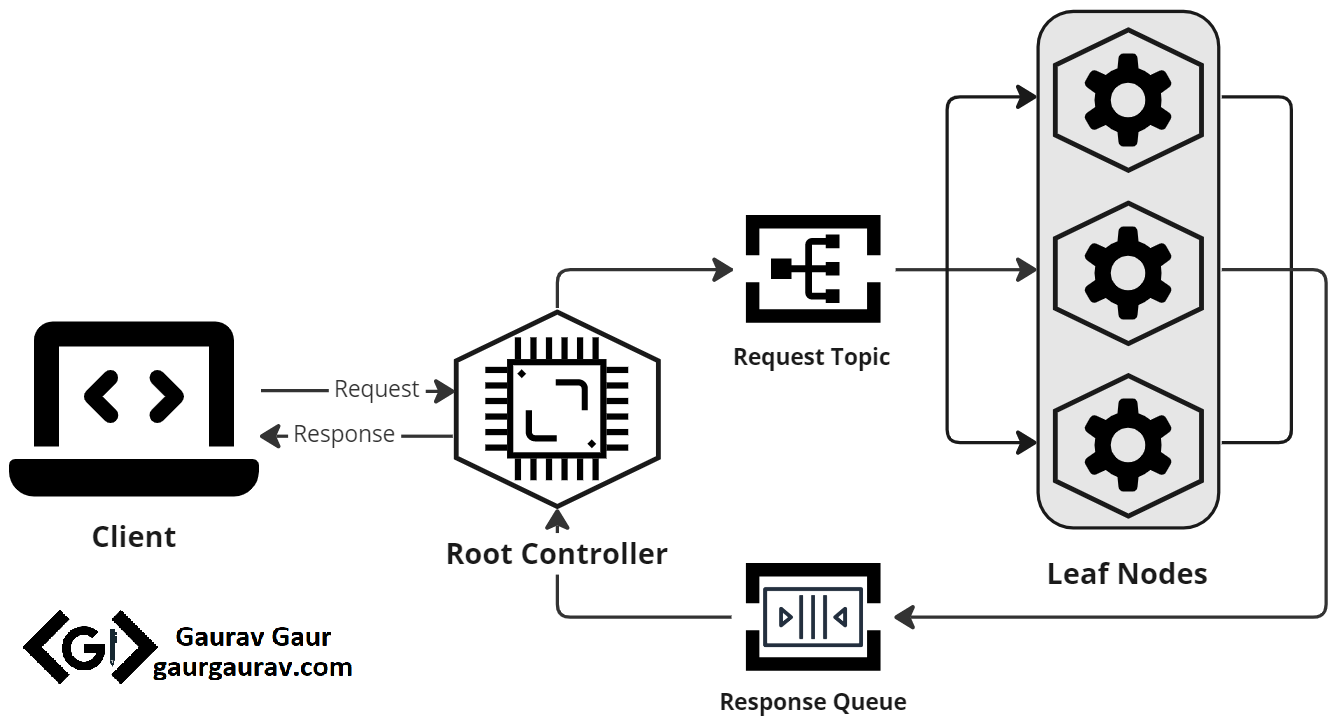 Scatter-Gather pattern implementation for decoupled root controller
Scatter-Gather pattern implementation for decoupled root controller
3. Asynchronous request processing
The pattern implementation discussed so far works best for immediate responses, ranging from a few milliseconds to a second. However, this implementation would not work for computation-intensive tasks, which can consume minutes to hours. Some examples of these computational tasks include data-intensive applications such as scientific simulations, data analytics, or machine learning. To effectively tackle these scenarios, it is essential to divide the root controller into two distinct components: a dispatcher and a processor. This division would enable us to process requests asynchronously. Below are the steps for such asynchronous communication.
- When a request comes in, the dispatcher accepts the request and generates a unique identifier. The dispatcher replies to the user with an estimated time to finish the task and provides the previously generated unique identifier to track the request.
- The request is then published to the leaf nodes.
- The leaf nodes process the request and send their results to a queue subscribed by the processor.
- The processor service combines the results received from individual processor leaves and persists them into a database.
- Once the estimated time has elapsed, the user can provide the unique identifier to fetch the result. If the result is unavailable within the estimated time, the processor can either request the user to check later or provide a partial result.
The figure shows a step-by-step asynchronous implementation.
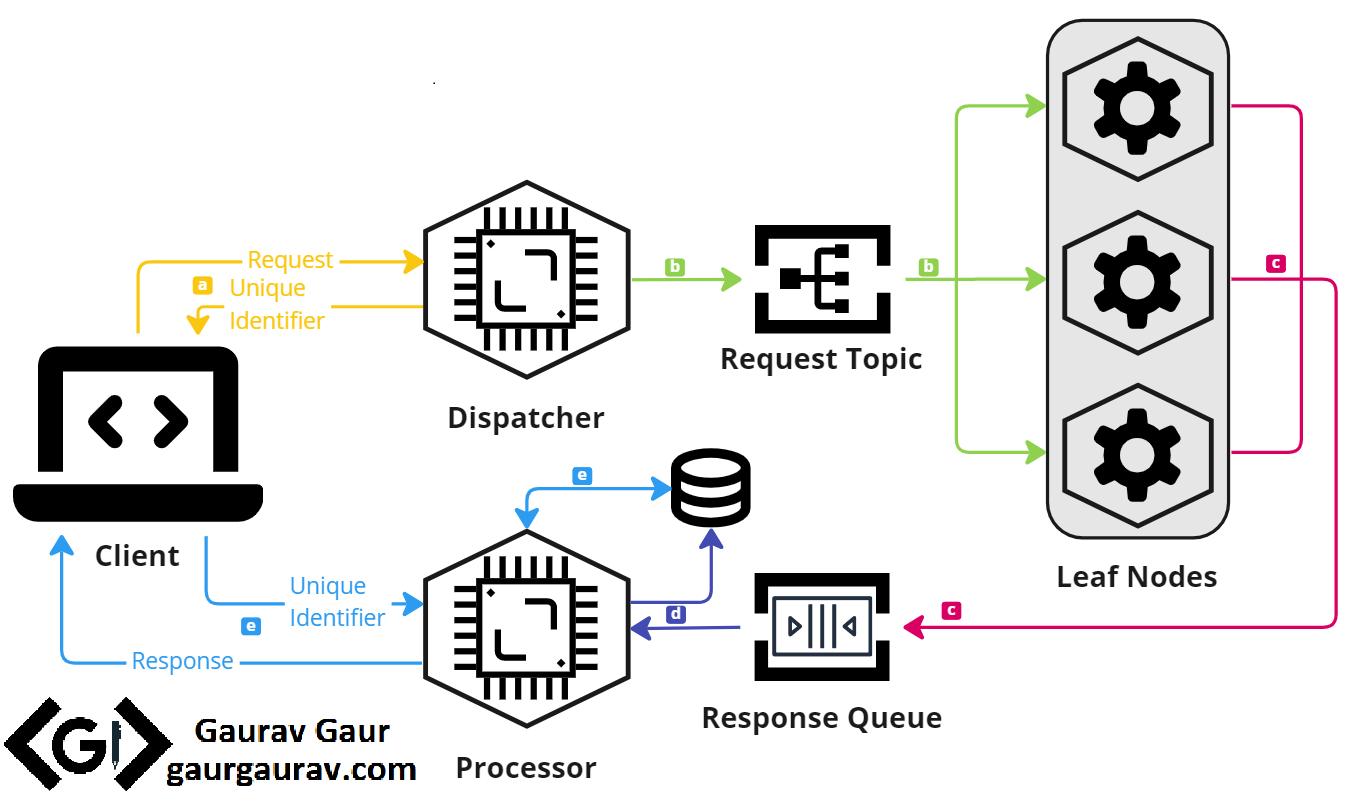 Scatter-Gather pattern asynchronous implementation
Scatter-Gather pattern asynchronous implementation
Important Considerations – Number of Leaf Nodes
After seeing the implementation in the previous section, the next crucial step is to choose the optimum number of leaf nodes. The pattern seems to suggest that adding more leaf processors and increasing parallelization can improve efficiency, but it comes at the cost of managing overhead.
- When a request comes in, the root controller must divide it, send it to the distribution infrastructure, and so on. While the cost of splitting, reading, and writing from the network is negligible at first compared to the computation logic, this cost grows as we scale leaf nodes. If parallelization continues, the overhead may exceed the computation cost.
- The next consideration is that the root controller waits for the result from all leaf nodes, which means the overall response time depends on the slowest node. It is commonly known as the “straggler” problem, and it can considerably delay the system’s completion time due to a single slow node. To mitigate the straggler problem, established techniques such as speculative execution and dynamic partitioning can distribute the load evenly.
- The most favourable number of leaf nodes also depends on the availability and accuracy of service. Suppose a service wants to achieve 97% availability without sacrificing the result, and the cloud vendor environment provides a leaf node at 99% availability. In this case, choosing scatter-gather seems to be the right choice. However, a careful calculation reveals that the service can have at most three processing leaves. Adding a fourth processing leaf might lead to an SLA breach, due to the probability of node failure (0.99 × 0.99 × 0.99 × 0.99 == 0.96). It gets even worse if we add more leaves.
Therefore, choosing the number of leaf nodes is critical for designing a successful scatter-gather implementation.
Summary
The scatter-gather pattern is a distributed computing pattern. The pattern has several advantages such as improved performance, increased fault tolerance, and better scalability. However, the choice of the optimal number of processing leaf nodes is vital to achieving high performance. Overall, the scatter-gather pattern is a powerful tool for developing high-performing distributed applications.