Pipes And Filters Pattern: Streamlining Data Processing in Distributed Systems
Pipes and Filters is scalable design pattern that break down monolithic task performing complex operations into series of reusable individual components.
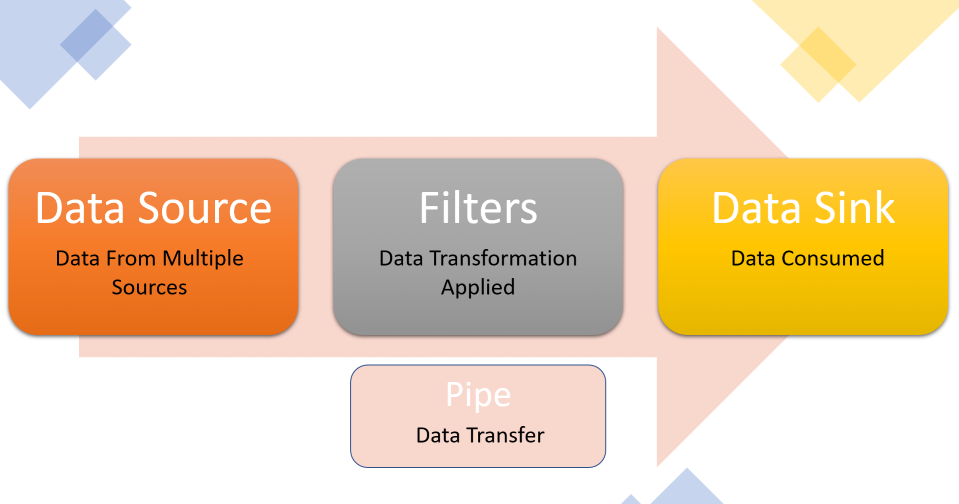
Introduction
Applications today collect an infinite amount of data. Many applications need to transform this data before applying any meaningful business logic. Tackling this complex data or a similar processor intensive task without a thought-through strategy can have a high-performance impact. This article introduces a scalability pattern – pipes and filters – that promotes reusability and is appropriate for such scenarios.
Problem Context
Consider a scenario where incoming data triggers a sequence of processing steps, where each step brings data closer to the desired output state. The origin of data is referred to as a data source. Examples of data sources could be home IoT devices, a video feed from roadside cameras, or continuous inventory updates from warehouses. The processing steps during the transformation usually execute a specific operation and are referred to as filters. These processing steps are independent and do not have a side-effect, i.e., running a step does not depend on any other steps. Each filtering step reads the data, performs a transforming operation based on local data and produces an output. Once the data has gone through the filters, it reaches its final processed stage where it is consumed, referred to as Data Sink. A straightforward implementation could be a complete service that takes the data input, performs all the steps sequentially and produce an output. The modules within the service perform the required step and pass on the data to the next module. Although the solution initially looks good as it hides all the complexity of data processing, the use of such a monolithic service will have listed problems:
- The solution limits code reuse.
- Any change in a processing filter step will lead to a release of all the filters.
- The slowest processing filter step can become a bottleneck impacting the overall throughput of the service.
- As the solution scales, it will scale all the processing steps. Such scaling will lead to excessive resource utilisation in the cloud when not intended.
Thus, the above approach is inflexible, non-scalable and against reusability. A good solution must address all the above concerns. Let us try to find a solution to this in the next section.
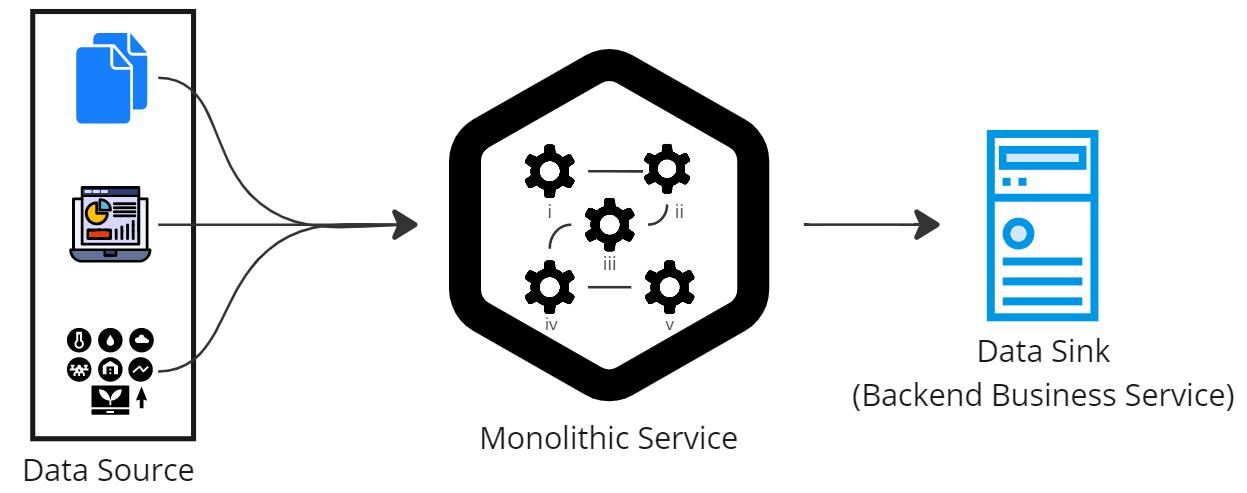 Monolithic Service with task modules
Monolithic Service with task modules
Solution
We can improve the suboptimal solution from the previous section by splitting the monolithic service into a series of components or functions, each performing a single processing filter step. These functions are combined to form a pipeline where functions receive a standard input and produce an accepted output. Such a decomposition will introduce loose coupling into the solution. It would allow effortless removal, replacement, rearrangement, or plug-in of a new filter step in pipelines. Moreover, it will enable code reuse if we need a similar processing filter in any other pipeline, the existing filters can be shared.
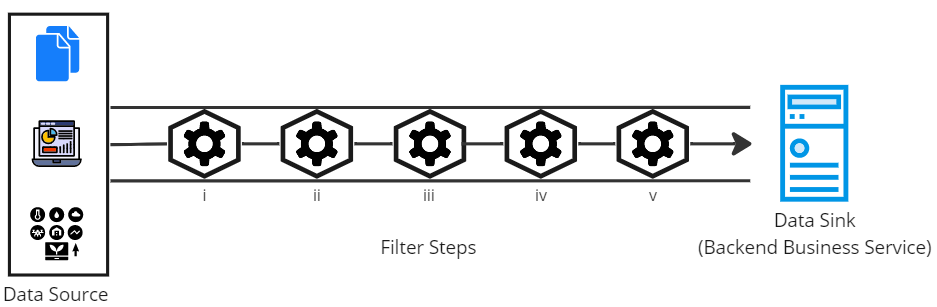 Pipes and Filters Solution
Pipes and Filters Solution
The solution also addresses the issue of the slowest processing filter step being a bottleneck, as it provides an opportunity to scale individual functions. The slowest running function can run parallel instances to spread the load and improve throughput. The individual scaling of components will also save us from any extra costs.
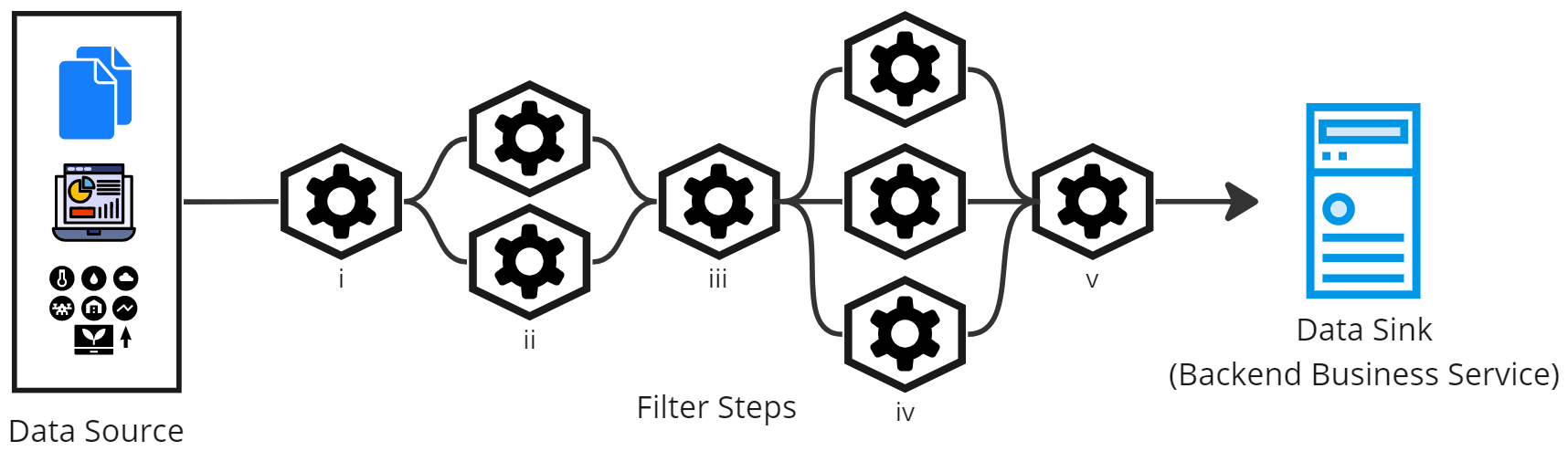 Pipes and Filters Solution Scaling Individually
Pipes and Filters Solution Scaling Individually
Finally, the processing filters can take advantage of cloud infrastructure. For instance, we can request a specific virtual machine based on the behaviour of a filter - processor-intensive or memory-intensive.
When to use this pattern
As we now have a better knowledge of the pattern, this section explores when to think about the pattern.
- The pattern is valuable for breaking down complex processing workflows, where each step is independent.
- The processing steps have distinctive hardware needs or scalability requirements, and, in some cases, even preferred programming language requirements.
- The pattern can address flexibility concerns in workflows where requirements and business processes are changing constantly.
- The pattern is efficient in removing bottlenecks in workflows by parallel and distributed processing of individual steps.
Important Considerations
The pattern has many advantages but consider the below points before adopting this pattern.
- The increased flexibility and clear separation come at the expense of complexity, especially when individual filter steps are too granular. Moreover, transferring data and communication between filters is an overhead.
- There is always a risk of losing the messages between the filters; thus, a thought-through strategy is needed to mitigate these scenarios.
- Like above, there is also a need for a recovery strategy if a pipeline fails. Can a new message be injected into the pipeline, or is there a provision to save the state of the pipeline?
- Each filter step must be stateless and must have sufficient context. Since these filter steps operate in isolation, each filter must be provided with enough inputs to work.
Implementation Details
Multiple implementations of the pattern are possible based on the nature of the solution.
Dynamic Pipeline Behaviour
Data-Driven Strategy: It is also known as a push strategy. The data source writes a message into the pipeline. Filters read the incoming message, process it, and push it further. Finally, the message reaches the data sink, where it is consumed.
Demand-Driven Strategy: A data-driven strategy pushes the message through the pipeline, while in a demand-driven strategy, a message is pulled. Whenever the data sink initiates a read, the data source produces a new message. The filters then process the new message, and the final transformed result is sent to the data sink in response to the original call.
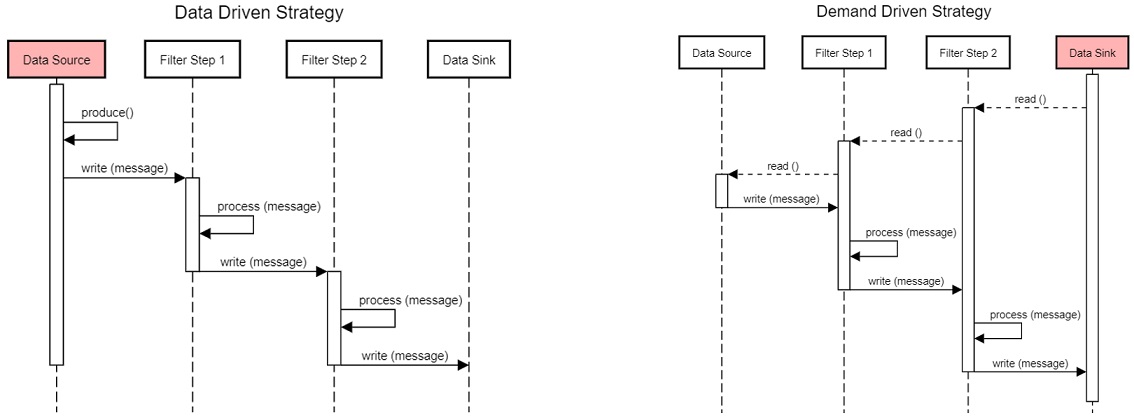 Pipes and Filters Dynamic Pipeline Behaviour
Pipes and Filters Dynamic Pipeline Behaviour
Message Behaviour
During the discussions until now, we notice that the message travels through the pipeline, typically via message brokers. However, we can skip sending the entire data through the pipeline. An alternative could be to store the data at a temporary location on a distributed file system or in a preferred database. Each filter step can pass the storage location of the data from where it can be read.
The implementation reduces the data travelling through the pipe. Moreover, the latest state of the data is always persisted in case the pipeline fails. But the disadvantage of the implementation is that it increases I/O operations, which increases the chances of exceptions.
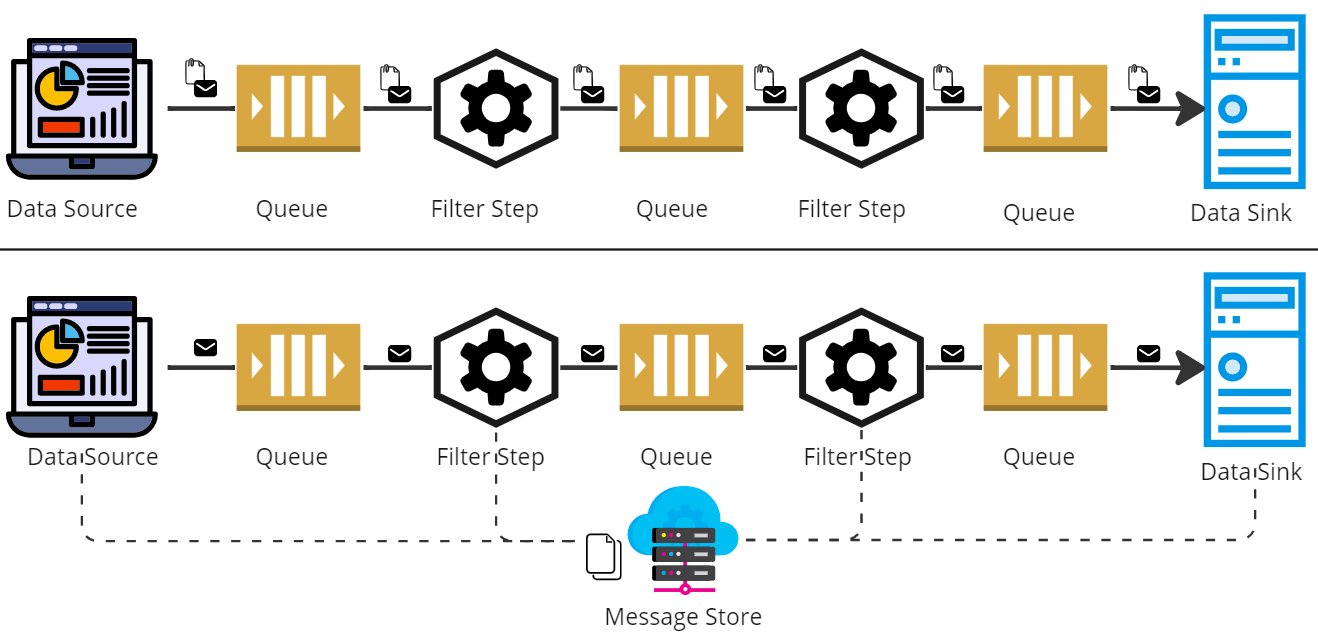 Pipes and Filters Dynamic Message Behaviour
Pipes and Filters Dynamic Message Behaviour
Filter Behaviour
The number of filters should be developed carefully in a pipeline. While designing filters, it is wise to break down a large filter into multiple constituent steps to minimize the complexity. On the other hand, filters that are light on processing can be combined into a single step to reduce the overhead. Filter steps introduced in a pipeline should be good enough to maximize concurrency, but small enough to minimize the overhead of transferring data through the pipeline stages.
Sample Use case
Previous sections have made clear how to use this pattern. This section provides an example to explain pattern usage. Let us say we are collecting a continuous stream of data for a machine learning project. Since the data is collected from multiple sources, the raw data could be in different formats, incomplete, or dirty. Raw data must be cleaned and structured before conducting any analysis on it. Data cleaning is a tedious and time-consuming process but is a necessary step to get a quality result. The data cleaning process consists of six steps, specifically
- Remove duplicates,
- remove irrelevant data,
- fix structural errors,
- filter unwanted outliers,
- handle missing data, and finally
- validate your data.
Although we can write a service that hides the complexity of data cleaning behind, it would have the same demerits as were listed earlier. It would be worth creating a pipeline for the data cleaning, as a couple of steps in the above pipeline may need specialized processing and hardware. Furthermore, there are multiple off-the-shelf tools available that can be used in the pipeline.
Summary
In the end, I would say that pattern helps create scalable applications. The pattern resembles a water supply system, where a stream of water flows through the channel via various filters. The number of filters installed on the supply channel is based on the final usage of water. For example, water supplied to a household will pass through more filters than water supplied for irrigation.