Orchestration Pattern: Managing Distributed Transactions
The article explains how to manage complex workflows of a distributed application using an Orchestration Pattern. The technique allows to create scalable, reliable, and fault-tolerant systems.

Introduction
As organizations migrate to the cloud, they desire to exploit this on-demand infrastructure to scale their applications. But such migrations are usually complex and need established patterns and control points to manage. In my previous blog posts, I’ve covered a few of the proven designs for cloud applications. In this article, I’ll introduce the Orchestration Pattern (also known as the Orchestrator Pattern) to add to the list. This technique allows to create scalable, reliable, and fault-tolerant systems. The approach can help us manage the flow and coordination among components of a distributed system, predominantly in a microservices architecture. Let’s dive into a problem statement to see how this pattern works.
Problem Context
Consider a legacy monolith retail e-commerce website. This complex monolith consists of multiple subdomains such as shopping basket, inventory, payments etc. When a client sends a request, the website performs a sequence of operations to fulfil the request. In this traditional architecture, each operation can be described as a method call. The biggest challenge for the application is scaling with the demand. So, the organisation decided to migrate this application to the cloud. However, the monolithic approach that the application uses is too restricted and would limit scaling even in the cloud. Adopting a lift and shift approach to perform migration would not reap the real benefits of the cloud.
Thus, a better migration would be to refactor the entire application and break it down by subdomains. The new services must be deployed and managed individually. The new system comes with all the improvements of distributed architecture. These distributed and potentially stateless services are responsible for their own sub-domains. But the immediate question is how to manage a complete workflow in this distributed architecture. Let us try to address this question in the next section and explore more about Orchestration Pattern.
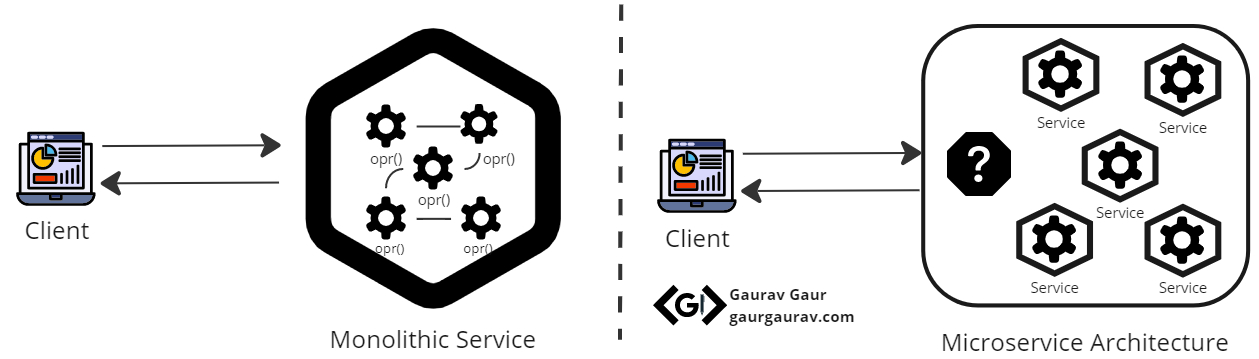 Monolithic application migration to cloud
Monolithic application migration to cloud
What is Orchestration Pattern
We have designed an appropriate architecture where all services operate within their bounded context. However, we still need a component that is aware of the entire business workflow. The missing element is responsible for generating the final response by communicating with all of the services. Think of it like an orchestra with musicians playing their instruments. In an orchestra, a central conductor coordinates and aligns the members to produce a final performance.
The Orchestration Pattern also introduces a centralized controller or service known as the orchestrator, similar to a central conductor. The orchestrator does not perform business logic but manages complex business flows by calling independently deployed services, handling exceptions, retrying requests, maintaining state, and returning the final response.
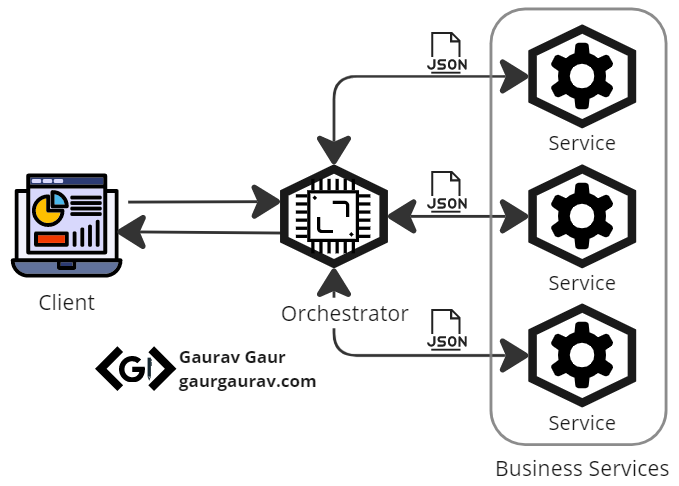 Orchestrator Pattern
Orchestrator Pattern
The figure above illustrates the pattern. It has three components: the orchestrator or central service, business services that need coordination, and the communication channel between them. It is an extension of the Scatter Gather pattern but involves a sequence of operations instead of executing a single task in parallel. Let’s examine a use case to understand how the pattern works.
Use Case
Many industries, such as e-commerce, finance, healthcare, telecommunications, and entertainment, widely use the orchestrator pattern with microservices. By now, we also have a good understanding of the pattern. In this section, I will talk about payment processing, which is relevant in many contexts, to detail the pattern in action.
Consider a payment gateway system that mediates between a merchant and a customer bank. The payment gateway aims to facilitate secure transactions by managing and coordinating multiple participating services. When the orchestrator service receives a payment request, it triggers a sequence of service calls in the following order:
- Firstly, it calls the payment authorization service to verify the customer’s payment card, the amount going out, and bank details. The service also confirms the merchant’s bank and its status.
- Next, the orchestrator invokes the Risk Management Service to retrieve the transaction history of the customer and merchant to detect and prevent fraud.
- After this, the orchestrator checks for Payment Card Industry (PCI) Compliance by calling the PCI Compliance Service. This service enforces the mandated security standards and requirements for cardholder data. Credit card companies need all online transactions to comply with these security standards.
- Finally, the orchestrator calls another microservice, the Transaction Service. This service converts the payment to the merchant’s preferred currency if needed. The service then transfers funds to the merchant’s account to settle the payment transaction.
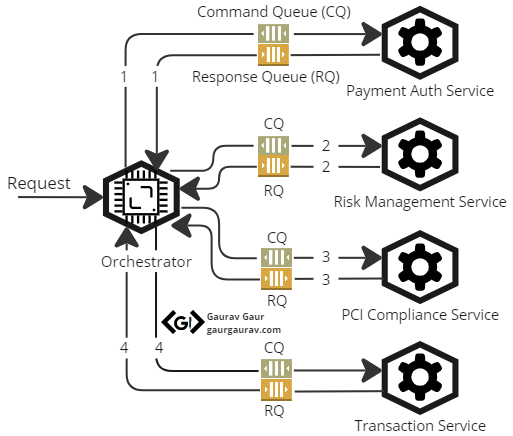 Payment Gateway System Flow
Payment Gateway System Flow
After completing all the essential steps, the Orchestrator Service responds with a transaction completion status. At this point, the calling service may send a confirmation email to the buyer. The complete flow is depicted in above diagram. It is important to note that this orchestration service is not just a simple API gateway that calls the APIs of different services. Instead, it is the only service with the complete context and manages all the steps necessary to finish the transaction. If we want to add another step, for example, the introduction of new compliance by the government, all we need to do is create a new service that ensures compliance and add this to the orchestration service. It’s worth noting that the new addition may not affect the other services, and they may not even be aware of it.
Implementation Details
The previous section has demonstrated a practical use case for managing service using an orchestrator. However, below are a few tactics that can be used while implementing the pattern:
Services vs Serverless
Mostly following this pattern means having a business logic that spreads across many services. However, there are specific situations when not all the business steps require execution or only a few steps are necessary. Should these steps be deployed as functions instead of services in these scenarios? Events usually trigger functions, which shut down once they complete their job. Such an infrastructure can save us money compared to a service that remains active continuously and performs minimal tasks.- Recovery from Transient Failures
The orchestration pattern implementation can be challenging because it involves coordinating multiple services and workflows, which requires a different approach to designing and managing software systems than traditional monolithic architectures. The implementation must be able to handle potential transient failures, such as network failure, service failure, or database failure. Below are a few ways to cater to such issues:- Retry Mechanism
Implementing a retry mechanism can improve resiliency when a service operation fails. The retry mechanism should configure the number of retries allowed, the delay between retries, and the conditions to attempt retries. - Circuit Breaker Pattern
In case a service fails, the orchestrator must detect the failure, isolate the failed service, and give it a chance to recover. It can help the service heal without disruption and avoid complete system failure. - Graceful Degradation
If a service fails and becomes unavailable, the rest of the services should continue to operate. The orchestrator should look for fallback options to minimize the impact on end-users, such as previously cached results or an alternate service.
- Retry Mechanism
Monitoring and Alerting
The entire business flow is distributed among various services when we operate with the Orchestration Pattern. Therefore, an effective monitoring and alerting solution is mandatory to trace and debug any failures. The solution must be capable of detecting any issues in real time and taking appropriate actions to mitigate the impact. It includes implementing auto-recovery strategies, such as restarting failed services or switching to a backup service, and setting up alerts to notify the operations team when exceptions occur. The logs generated by the orchestrator are also valuable for the operations team to troubleshoot errors. We can operate smoothly and meet user needs by proactively identifying and resolving issues.- Orchestration Service Failure
Finally, we must prepare for scenarios where the orchestrator fails itself while processing requests. For instance, in our payment gateway example, imagine a scenario where the orchestrator calls the Transaction service to transfer the funds but crashes or loses connection before getting a successful response for the occurred transaction. It could lead to a frustrating user experience, with the risk of the customer being charged twice for the same product. To prevent such failure scenarios, we can adopt one of the following solutions:- Service Replication
Replicate the orchestration service across multiple nodes. The service can automatically failover to the backup node when needed. With a load balancer that can detect and switch to the available node, the replication guarantees seamless service and prevents disruptions to the user. - Data Replication
Not only should we replicate the service, but we should also replicate the data to ensure data consistency. It enables the backup node to take over seamlessly without any data loss. - Request Queues
Implementing queues functions like a buffer for requests when the orchestration service is down. The queue can hold incoming requests until the service is available again. Once the backup node is up and running, it can retrieve the data from the queue buffer and process them in the correct order.
- Service Replication
Why use Orchestration Pattern
The pattern comes with the follwoing advantages:
- Orchestration makes it easier to understand, monitor and observe the application, resulting in a better understanding of the core part of the system with less effort.
- The pattern promotes loose coupling. Each downstream service exposes an API interface and is self-contained, without any need to know about the other services.
- The pattern simplifies the business workflows and improves the separation of concerns. Each service participates in a long-running transaction without any need to know about it.
- The orchestrator service can decide what to do in case of failure making the system fault-tolerant and reliable.
Important Considerations
The primary goal of this architectural pattern is to decompose the entire business workflow into multiple services, making it more flexible and scalable. And due to this, it’s crucial to analyse and comprehend the business processes in detail before implementation. A poorly defined and overly complicated business process will lead to a system that would be hard to maintain and scale.
Secondly, it’s easy to fall into the trap of adding business logic into the orchestration service. Sometimes it’s inevitable because certain functionalities are too small to create their separate service. But the risk here is that if the orchestration service becomes too intelligent and performs too much business logic, it can evolve into a monolithic application that also happens to talk to microservices. So, it’s crucial to keep track of every addition to the orchestration service and ensure that its work remains within the boundaries of orchestration. Maintaining the scope of the orchestration service will prevent it from becoming a burden on the system, leading to decreased scalability and flexibility.
Summary
Numerous organizations are adopting microservice patterns to handle their complex distributed systems. The orchestration pattern plays a vital role in designing and managing these systems. By centralizing control and coordination, the orchestration pattern enhances agility, scalability, and resilience, making it an essential tool for organizations looking to modernize their infrastructure.